We are using cookies.
We are using cookies on this web page. Some of them are required to run this page, some are useful to provide you the best web experience.
Privacy settings
Here is an overview of all cookies use
Cookies for Statistics
Statistic cookies anonymize your data and use it. These information will help us to learn, how the users are using our website.
Show Cookie Informationen
Google Conversion-Tracking-Tag

Künstliche Intelligenz (KI):
Künstliche Intelligenz bezeichnet die Fähigkeit von Computern oder Maschinen, Aufgaben auszuführen, die normalerweise menschliche Intelligenz erfordern. Dazu gehören Mustererkennung, Problemlösung, Entscheidungsfindung und das Lernen aus Daten. KI-Systeme nutzen Algorithmen und Modelle, um Informationen zu analysieren, Vorhersagen zu treffen oder Aktionen durchzuführen, die auf den verfügbaren Daten basieren.
Generative KI:
Generative KI ist eine spezielle Kategorie von KI-Systemen, die darauf ausgelegt sind, neue Inhalte zu erzeugen. Diese Inhalte können Texte, Bilder, Musik, Videos oder andere Datenformate sein. Generative KI-Modelle basieren häufig auf tiefen neuronalen Netzwerken, die aus umfangreichen Datenmengen trainiert werden. Ein bekanntes Beispiel für generative KI ist die Fähigkeit, realistische Bilder oder flüssige Texte zu erstellen, die von menschlicher Arbeit kaum zu unterscheiden sind.
Wichtig bei der Verwendung generativer KI ist die Qualität der Eingabe, des sogenannten „Prompts“. Dieser entscheidet über die Qualität, Umfang und Ausrichtung der Antwort.
Large Language Models (LLMs):
Large Language Models sind eine Unterkategorie der generativen KI, die speziell für die Verarbeitung und Erzeugung natürlicher Sprache entwickelt wurden. Sie basieren auf riesigen neuronalen Netzen, die auf umfangreichen Textdatensätzen trainiert werden. LLMs, wie beispielsweise GPT (Generative Pre-trained Transformer), können komplexe sprachliche Aufgaben wie das Verfassen von Texten, Beantworten von Fragen, Übersetzen von Sprachen oder Zusammenfassen von Inhalten ausführen. Ihre Stärke liegt in ihrer Fähigkeit, kontextbezogene und kohärente Antworten auf Eingaben zu generieren.
Grundsätzlich steht die htw saar der Verwendung von KI-Werkzeugen in Studium und Lehre positiv gegenüber. Studierende sollten im Rahmen ihres Studiums die (KI-)Kompetenzen erwerben, die sie ihn ihrem zukünftigen beruflichen Umfeld benötigen.
Jedoch ist ein sinnvoller Einsatz kontextabhängig (insbesondere im Hinblick auf die Lernziele) und sollte situativ zwischen Lehrenden und Studierenden abgestimmt und klar definiert werden, insbesondere wenn es um die Erstellung der Prüfungsleistung geht. Es ist darauf zu achten, dass alle Studierenden Zugang zu benötigten KI-Tools haben (Chancengleichheit) und dass sie über rechtliche Aspekte (Datenschutz, Urheberrecht) sowie Nutzungsbedingungen informiert wurden. Dies betreffen auch die Konsequenzen bei einem Verstoß gegen derart getroffene Vereinbarungen.
Allen Studierenden muss bewusst sein, dass sie selbst für die Qualität ihrer (wissenschaftlichen) Arbeit verantwortlich sind. Die Erstellung einer solchen Arbeit stellt eine signifikante geistige Eigenleistung dar. Daher müssen Studierende den kompletten Schreibprozess selbst steuern und verantworten.
Es kann auch sein, dass bei Lehrveranstaltungen, wo es beispielsweise um das Erlernen von Schreibkompetenzen geht, KI-Schreibwerkzeuge explizit verboten werden. Dies sollte dann jedoch vom Lehrenden begründet und klar kommuniziert werden.
Grundsätzlich ist zu beachten, dass eine KI das sogenannte „deep reading“ nicht ersetzen kann. Es gibt klare neurowissenschaftliche Hinweise, dass das von der KI Produzierte sich nicht im Langzeitgedächtnis verankern kann und daher nach einiger Zeit nicht mehr abrufbar ist. Das heißt, das eigene konzentrierte Lesen, dem Nachgehen einer Begründung und das eigene reflektierte Einordnen kann nicht über KI ersetzt werden.
Die folgende Tabelle [1] gibt einen Überblick darüber, für welche Einsatzzwecke KI-Tools bei schriftlichen Ausarbeitungen verwendet werden dürfen. Außerdem wird dort aufgeführt, in welchen Fällen die Verwendung kenntlich gemacht werden soll.
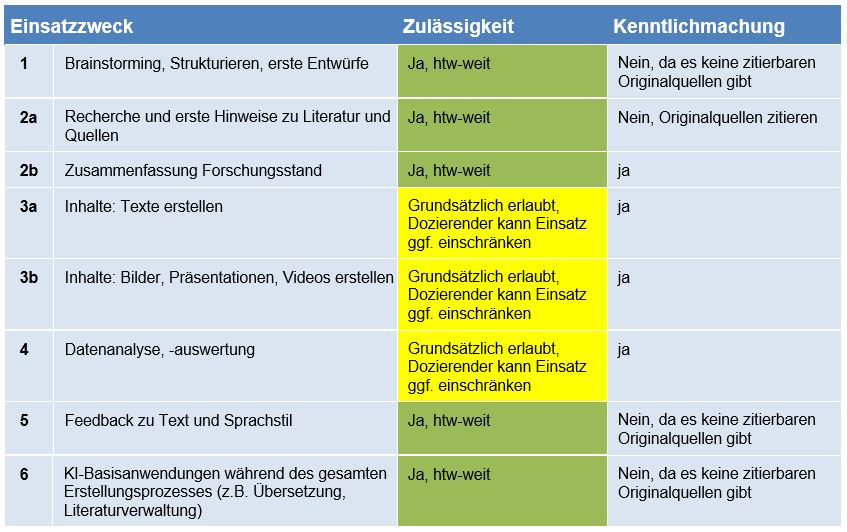
[1] In Anlehnung an: Staubach, Juliane; Dick, Thorsten: Zulässigkeit und Kenntlichmachung von KI in schriftlichen Prüfungen. In: Die Neue Hochschule, 2024-4, S. 30–31.
Grundsätzlich soll der Einsatz von KI-Tools bei der Ausarbeitung einer wissenschaftlichen Arbeit oder Prüfungsleistung gekennzeichnet werden, um der guten wissenschaftlichen Praxis und dem Prüfungsrecht Rechnung zu tragen. Siehe hierzu die Tabelle in Nr. 3 mit möglichen Einsatzzwecken und Hinweisen zur Kenntlichmachung.
Ein möglicher Vorschlag zur Kennzeichnung sieht wie folgt aus [1]:
Art und Umfang der Kennzeichnung können bei Bedarf von den Prüfenden angepasst werden. Dies sollte dann an die Studierenden kommuniziert werden.
[1] In Anlehnung an: Thiel, Andrea; Model, Benedikt; Staubach, Juliane; Dick, Thorsten; Bringezu, Ute: EMPFEHLUNG Kenntlichmachung KI-generierter Inhalte in schriftlichen Prüfungen 24.10.2024 – 3. Auflage, Technische Hochschule Mittelhessen (https://www.thm.de/site/component/edocman/2394-empfehlung-kenntlichmachung-ki-generierter-inhalte-in-schriftlichen-pruefungen/download.html)
Generative Künstliche Intelligenz (KI) wie ChatGPT oder andere Sprachmodelle können vielseitige Unterstützung, von der Erstellung von Texten bis hin zur Beantwortung komplexer Fragen bieten. Gleichzeitig stellt sich dabei jedoch die Frage, wie zuverlässig die von solchen Systemen bereitgestellten Informationen sind. Generative KI wurde auf riesige Mengen von Textdaten trainiert, die aus unterschiedlichsten Quellen stammen. Dadurch kann sie große Wissensmengen auf Abruf bereitstellen, was bei der Recherche oder Ideenfindung nützlich sein kann. Oft stellt sie Informationen in einem breiten Kontext dar, um ein Thema zu beleuchten. KI erzeugt dabei oft grammatikalisch und stilistisch korrekte Texte, die einen professionellen Eindruck machen.
Trotz dieser Vorteile gibt es gravierende Einschränkungen im Hinblick auf fehlende Gewährleistung der Richtigkeit. Generative KI kann faktisch falsche oder ungenaue Informationen liefern. Diese entstehen, wenn die zugrunde liegenden Trainingsdaten Fehler enthalten oder wenn das Modell Informationen in einen falschen Zusammenhang bringt. Dabei ist das sogenannte Halluzinationen ein bekanntes Problem von Sprachmodellen, bei dem die KI scheinbar plausible, aber inhaltlich falsche Fakten oder Quellen erfindet. Auch ist die Aktualität nicht immer gewährleistet, da die Trainingsdaten von generativer KI oft zu einem bestimmten Zeitpunkt enden. Informationen, die danach veröffentlicht wurden, sind ihr unbekannt. Zudem kann KI keine Quellen bewerten oder die Vertrauenswürdigkeit von Informationen eigenständig einschätzen.
Um die Faktentreue zu überprüfen und potenzielle Fehler zu minimieren, sollten Studierende und Lehrende folgende Strategien anwenden:
Wichtig: Sie als Anwender*innen der KI-Werkzeuge verantworten vollständig die Ergebnisse!
Fast alle KI-Tools sind NICHT datenschutzkonform. Sie dürfen daher dort keine personenbezogenen oder sensiblen Daten (z.B. Namen, Matrikelnummer, vertrauliche Daten) eingeben – weder von sich selbst oder anderen. Eine Einteilung verschiedener Arten von Daten nach Schutzklassen finden Sie hier: https://moodle.htwsaar.de/pluginfile.php/320505/mod_resource/content/0/Datenschutzklassen.pdf
Sie sind verpflichtet, bei jedem KI-Tool, welches Sie verwenden, sich über die Nutzungsbedingungen und Datenschutzhinweise zu informieren und gemäß diesen die Werkzeuge zu nutzen. Bei Unsicherheit wenden Sie sich bitte an die Abteilung „Recht, Akademische Angelegenheiten und Datenschutz“ (A5).
Eine Ausnahme bietet das HAWKI-System der htw saar. Dieses ist datenschutzkonform, da die darin enthaltenen LLMs inkl. ChatGPT dort über eine API angebunden sind. Somit können die Chatanfragen nicht einzelnen Personen zugeordnet werden. Des Weiteren werden die Chatinhalte nicht zu Trainingszwecken der LLMs weiterverwendet. Dennoch sollten keine sensiblen oder personenbezogenen Daten eingegeben werden, da die htwsaar die Verwendung von Daten der Schutzklassen 2 und 3 ohne besondere Maßnahmen in IT-Systemen außerhalb der Hochschule nicht erlaubt.
Es gibt kein Urheberrecht auf den Output aus einer generativen KI, d.h. dieser ist gemeinfrei. Dennoch können durch Erzeugung des Outputs unter Umständen Urheberrechte Dritter verletzt werden, da möglicherweise beim Training der Large Language Models urheberrechtlich geschützte Daten verwendet wurden. Hierzu fehlen aktuell noch klare gesetzliche Regelungen. Bitte beachten Sie bei den von Ihnen verwendeten KI-Werkzeugen immer die jeweiligen Nutzungs- und Lizenzbedingungen.
Verantwortlich für die Bewertung studentischer Prüfungsleistungen ist grundsätzlich der/die Prüfer*in. Diese Verantwortung kann nicht an eine KI abgegeben werden.
Außerdem sind Haus-, Projekt-, Seminar- und Abschlussarbeiten geistiges Eigentum der Studierenden und dürfen ohne deren Einwilligung nicht in KI-Werkzeuge hochgeladen werden. Auch hier sind die Aspekte des Urheberrechtes und des Datenschutzes zu berücksichtigen.
Informationen hierzu finden Sie in folgenden Moodlekursen:

Mediendidaktik

Digital gestützte Lehr- und Lernszenarien